- 10 Best Practices for Jakarta EE Performance Optimization
- Performance Best Practice no. 1: Optimize database operations
- Performance Best Practice no. 2: Implement Caching
Database operations are a very critical part of most applications in regards of performance. There are multiple reasons why database operations can significantly contribute to lower performance:
- The database often runs on a remote server, slowing down communication with the database and the data transfer
- Establishing individual connections to a database can take a significant portion of time compared to running the whole database query
- Database queries can run for a long time
- Network communication is unstable and may required restarting queries in case of network failures
You can address the above issues and boost Jakarta EE database performance by leveraging the following best practices.
- Adjust connection pool sizes to align with workload requirements
- 🛈 Tip: Thread pool max size should be usually bigger than connection pool max size.
- 🛈 Tip: Connection pool max size should reflect the maximum number of connections allowed by the database.
- 🛈 Tip: Connection idle timeout (time after which unused connections are closed) should be shorter than on the database side to avoid reusing stale connections if the database already closed them.
- Use Prepared Statements and reuse them when calling the same query to avoid repetitive SQL parsing
- 🛈 Tip: When using Jakarta Persistence (JPA) queries, prepared statements are used automatically by the persistence provider
- Implement statement caching to cut down on SQL parsing overhead. This is another way of reusing previous statements for the same query
- Enable JDBC batching or JPA batching to handle multiple SQL operations efficiently
“Connection establishment is the most expensive database operation; the obvious optimization that Java developers have been using for ages is connection pooling which avoids creating connections at runtime (unless you exhaust the pool capacity).” – Kuassi Mensah [1]
How GlassFish helps with improving database performance
GlassFish provides built-in connection pools. If an application uses a datasource defined in GlassFish, connections are managed by GlassFish via the built-in connection pooling mechanism and can be configured externally, outside of your application, via GlassFish Admin Console or admin commands.
JDBC statement caching involves storing frequently executed SQL statements, such as Statement, PreparedStatement, and CallableStatement, in a cache, so that they can be reused later if the same request is executed again. Instead of preparing an SQL statement from scratch every time it needs to be executed, an already prepared statement is used if it’s stored in the cache. While statement caching is often a built-in feature of JDBC drivers, GlassFish provides its own statement caching mechanism that can be used even with JDBC drivers that do not have native support for it[2].
Connection pool configuration
You can configure connection pools in the Admin Console as follows:
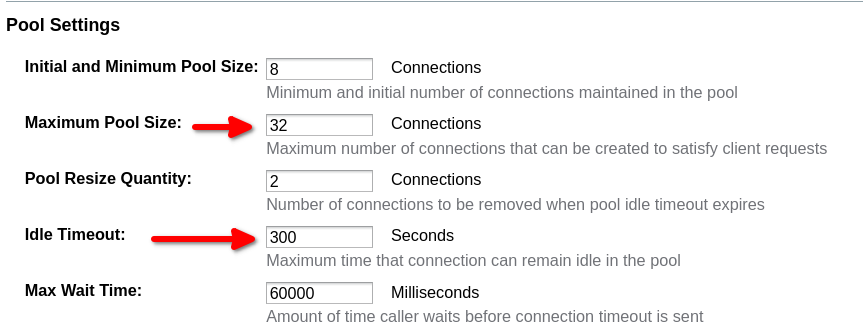
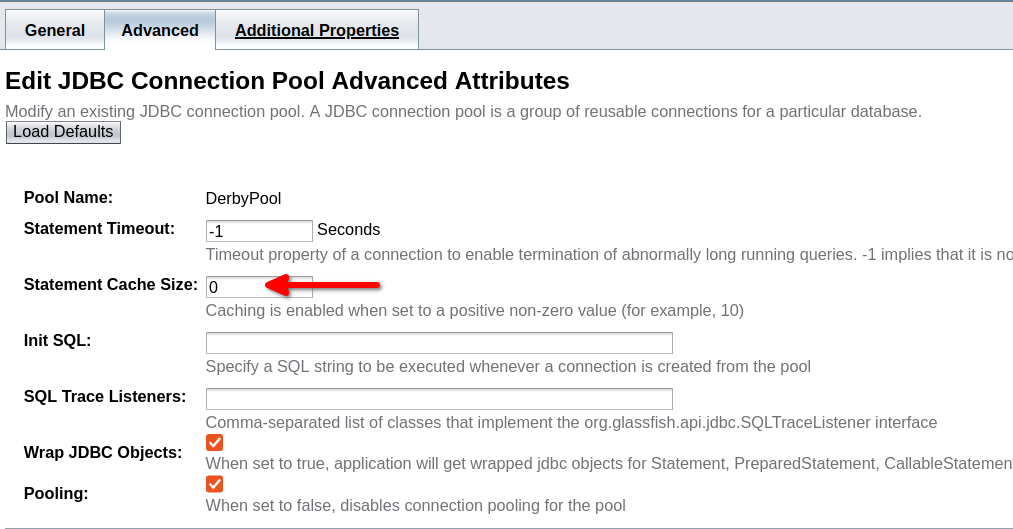
Or set the following properties (using the set admin command or as Embedded GlassFish properties):
resources.jdbc-connection-pool.{CONNECTION_POOL_NAME}.max-pool-size=32
resources.jdbc-connection-pool.{CONNECTION_POOL_NAME}.idle-timeout-in-seconds=300
resources.jdbc-connection-pool.{CONNECTION_POOL_NAME}.statement-cache-size=10If you define the datasource in an application in web.xml:
<data-source>
<name>java:app/jdbc/MyDatasource</name>
<max-pool-size>32</max-pool-size>
<max-idle-time>300</max-idle-time>
<max-statements>10</max-statements>
</data-source>Or using in an application using an annotation:
@DataSourceDefinition(
name = "java:app/jdbc/MyDatasource",
maxPoolSize = 32,
maxIdleTime = 300,
maxStatements = 10
)JDBC batching
JDBC batching is a feature in Java Database Connectivity (JDBC) that allows you to group multiple SQL statements together and send them to the database in a single request. In other words, the batched statements will not be executed immediately when they are submitted, but will be submitted together in a single request after the last statement is submitted.
Here’s an example, how to execute multiple JDBC statements in a batch:
Statement statement = connection.createStatement();
statement.addBatch("INSERT INTO CITIES(ID, NAME, COUNTRY) "
+ "VALUES ('1','Zagreb','Croatia')");
statement.addBatch("INSERT INTO CITIES(ID, NAME, COUNTRY) "
+ "VALUES ('2','Dublin', 'Ireland')");
statement.executeBatch();Jakarta Persistence (JPA) batching
With JPA (Jakarta Persistence), a batching behavior can be enabled via EclipseLink extensions for JPA. If your applications use Hibernate or another JPA provider, these wouldn’t be available to you. In that case, check the documentation of your provider if it supports similar extensions.
To enable the batching behavior, configure the following JPA properties (for example in persistence.xml or when creating an EntityManager):
eclipselink.jdbc.batch-writingwith the valuejdbc(to use JDBC batching) under the hood) orbuffered(to use batching provided by EclipseLink). EclipseLink also providesoracle-jdbcoption works only with Oracle DB JDBC driver, andcustom-class, which allows providing a completely custom mechanism- Optionally, specify the
jdbc.batch-writing.sizeproperty with the size of the batch (number of the statements in a single batch)
For example, in persistence.xml:
<property name="eclipselink.jdbc.batch-writing" value="jdbc"/>
<property name="eclipselink.jdbc.batch-writing.size" value="150"/>This will enable batching for all data-writing JPA operations. If you want to invoke a certain statement in a JPA query without the batching behavior, you can then disable batching with the jdbc.batch-writing query hint.
For example:
query.setHint("jdbc.batch-writing", false);Or, if you compile your application against EclipseLink API:
import org.eclipse.persistence.config.HintValues;
import org.eclipse.persistence.config.QueryHints;
...
query.setHint(QueryHints.BATCH_WRITING, HintValues.FALSE);Next Steps
To put these ideas into action, you should think about how your application works with the database, what are your database settings, and how much load (parallel queries and connections) your database can handle. Then prepare a tuned configuration, test how it works, and always monitor performance to see if there are any bottlenecks or space to tune the configuration even further. In this case, it’s worth monitoring the amount of database connections, how many of them are being actively used, average length of query execution, etc.
In the next article, we’ll go into more details about implementing caching mechanisms to avoid wasting time with repetitive tasks that provide the same output. So stay tuned…
